稳狗足球足球预测模型实战文章分类,整理竞彩足球分析方法、比赛复盘、联赛规律、冷门风险和足球数据工具应用内容,方便读者按类别连续阅读。
当前分类共 22 篇文章,也可以切换到其他分类。
概率校准检查的是模型概率是否可信。模型说 70%,长期类似样本真实发生率也应接近 70%。
Brier Score 用平方误差评估概率预测。它比命中率更细,比 LogLoss 更直观,适合检查模型概率偏差。
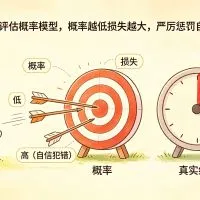
LogLoss 用来评估概率模型。模型给真实结果的概率越低,损失越大,尤其会严厉惩罚自信地犯错。
LightGBM 的核心不是“神奇算法”,而是用一棵棵树不断修正前面模型的错误,逐步降低预测损失。
逻辑回归不是简单分类器,它通过 sigmoid 或 Softmax 把特征组合转成概率,是足球模型里最重要的可解释基线之一。
泊松分布用一个预期进球 λ,计算球队进 0 球、1 球、2 球、3 球的概率,是足球比分模型的基础工具。
大数定律说明,样本越多,平均结果越接近真实概率。足球模型不能用几场比赛判断好坏。
方差衡量的是结果波动。足球模型即使长期有优势,短期也会出现连对、连错和明显回撤。
期望值衡量的是长期平均结果。足球模型不能只看命中率,还要看概率、回报结构和错误成本。
概率不是确定答案。足球模型输出 60%,意思是长期类似比赛大约发生 60%,不是这一场一定发生。
足球预测系统真正的难点,不是训练出一次好模型,而是长期更新、监控、校准、复盘和产品化表达。
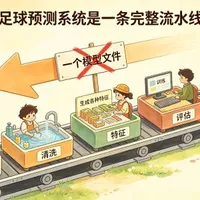
足球预测系统不是一个模型文件,而是一条从数据、清洗、特征、训练、评估到结果输出的完整流水线。
足球模型短期表现好,不代表长期可靠。模型失效通常来自过拟合、未来数据泄漏、样本漂移和特征污染。
足球模型评估不能只看命中率。真正重要的是概率是否可信、长期是否稳定、回测是否没有泄漏。
多模型融合不是简单投票,而是让不同模型从进球分布、线性基线和复杂特征三个角度互相校验。
胜平负模型不是只判断谁赢,而是输出主胜、平局、客胜三类概率。逻辑回归适合做可解释基线,LightGBM 适合学习复杂非线性关系。
泊松模型的核心不是猜比分,而是先估计主客队预期进球,再计算比分和总进球概率分布。
标签决定模型到底学什么。胜平负、总进球、比分、半全场属于不同预测目标,不能混在一起训练。
特征工程不是堆字段,而是把球队实力、状态、赛程、主客场和联赛环境转成赛前可用信号。
足球模型不是算法越复杂越好。数据不干净,队名、时间、赛制、缺失值和未来数据都会让模型失真。
足球模型不是数据越多越好,而是必须区分赛前可用数据、赛后结果数据和训练标签。
足球预测模型不是猜中比分,而是用历史数据训练出更可信的胜平负、进球数和比分概率。